Informatica Data Movement Mode
每个workflow都会指定一个集成服务来运行,而每个集成服务都必须指定一个DataMovementMode。不过简单地是,DataMovementMode只有两个选择
- ASCII
- Unicode
一个Domain里可以添加多个集成服务。
设置集成服务的DataMovementMode
需要登录到Administrator Console里,选择集成服务,在PowerCenter Integration Service Properites 栏里,就可以看到DataMovementMode,你可以编辑它,选择需要的模式。
差异
其实这个设置,很多人都没有太注意。但是这个选项确实有很大的影响。
- 是否转码
ASCII不转码,UNICODE会转码
ASCII模式
garbage-in,garbage-out模式,就是数据怎么进来的,就怎么出去,乱码等等问题,都不管,比较任性。
UNICODE模式
UNICODE模式会先转换成UCS-2中间编码,然后在转换成目标编码,见下图
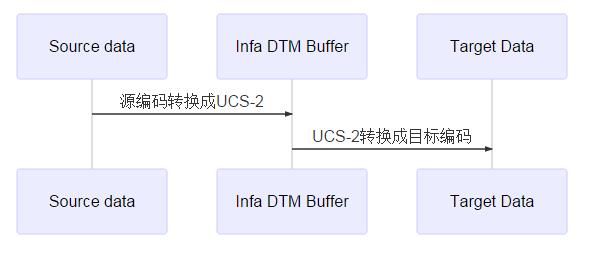
前面写了很多关于字符集编码的东西,在这里才能真正体现。
但是某种程度上UNICODE模式的性能会有所下降。但是这种差距并不是很大。
使用场景
从差异就可以看出使用场景了。一般来说,如果源和目标的编码不一致,那么就需要使用UNICODE模式。
下面着重讲一下一些特殊情况
源是单字节存储多字节字符
特别是以前的老系统,在oracle系统里使用一些WE8MSWIN1252字符集,但是存储的是汉字。但是目标系统却是AL32UTF8或者ZHS16GBK字符集编码。
这种情况下,直接使用UNICODE或者ASCII来抽取,100%会是乱码。
解决方案分为两个阶段
ASCII模式输出到文本文件
这里使用ASCII模式的不转码特性,将单字节字符写入到文本文件,让字符得到重组。
注意,这里文本文件的编码没有任何影响,因为ASCII模式不转码。
UNICODE模式写入到目标数据库
将第一个阶段生成的文本文件做为源,处理之后写入到目标数据库中。
注意,这里的文本文件的编码十分重要,你或许需要一些额外的工具来检测它的编码,例如word。
原因有两个,1)如果单字节字符集数据库存储多字节字符时,与你录入数据的编码有关。 2)UNICODE模式会根据文本文件字符集来转码。
字符超出了UCS-2编码范围
前面我们提到过UCS-2编码的局限性,在处理这些字符时,UNICODE模式并不能正确处理,所以会导致输出结果出现16进制符号等乱码情况。
这里只是提供我想到的解决方案
- 如果整个过程不需要转码,那么请使用ASCII模式
如果需要转码,而又不需要处理这些字段,那么可以使用base64等类似函数,先将这些字符转换一下,然后在处理,最后以base64转换之后的字符写入目标数据库或者临时文件
如果是临时文件,需要注意它的字符集编码应该与目标数据库的字符集编码一致。 然后在mapping中调用逆函数,那么再利用ASCII模式,将数据正确地写入到目标数据库。
NLS_LANG对转码的影响
如果没有使用oracle Native connection,即没有调用oracle client的连接方式,这个环境变量对转码没有影响。
如果使用了Oracle Native Connection,那么此参数决定了从oracle抽取数据的正确性。
所以如果你的环境中有多个Oracle 字符集编码系统,那么可能需要多个集成服务,那么可以在每个集成服务上设置此环境变量。【Administrator Console -> 集成服务 -> Processes -> Environment Variables】
Workflow中源和目标使用了不同的字符集编码
可以一个使用Native Connection,一个使用ODBC Connection方式。
或者
两个都使用Native Connection,在目标Connection上设置编码[例如:UTF-8]与目标数据库的编码【例如:gbk】不一致,但是兼容的编码。
第二种情况是利用oracle client会自动转码的特性,但是没有经过严格的测试,所以,推荐第一种方式。
Author: Arthur Li
Email: [email protected]
欢迎转载和关注微信号: INFAer